{kind=link}
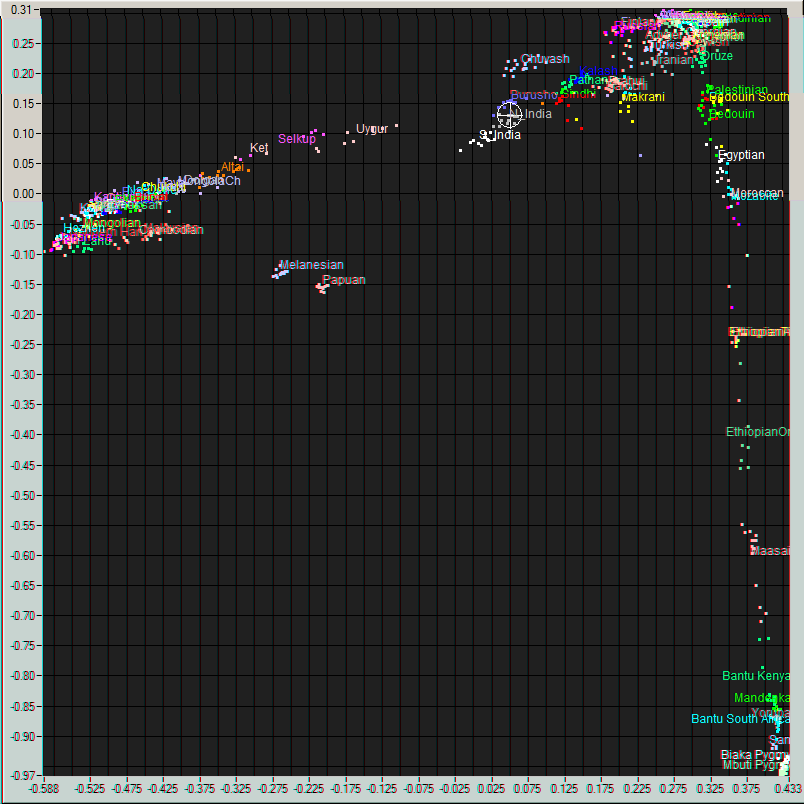
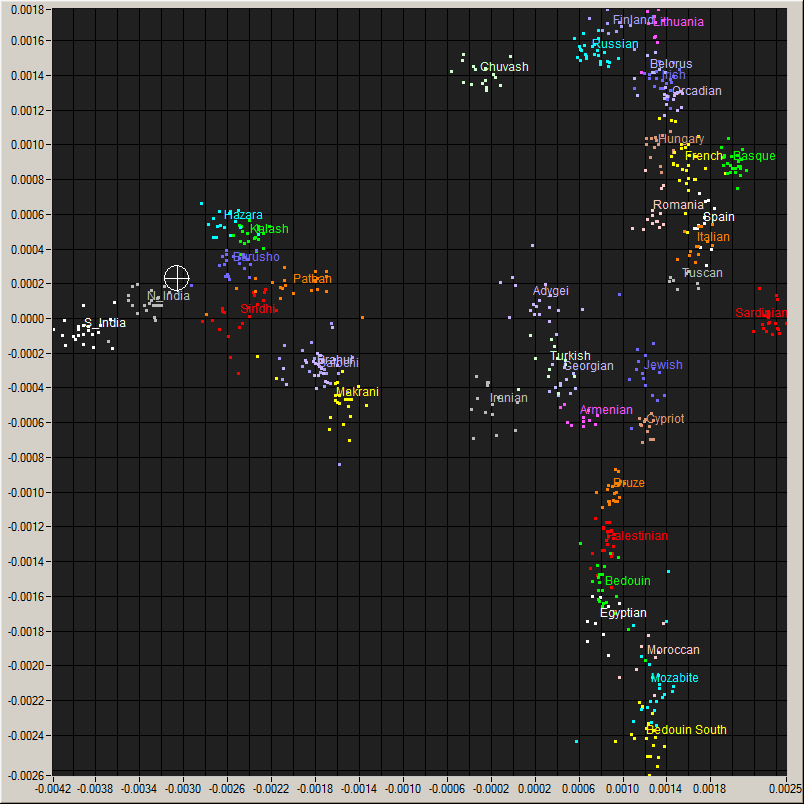
Me (Cross hair) on a plot of World populations and an enlarged view of the region around me..
Genealogical research in Hindu India is paradoxically both very simple and difficult at the same time. Even though every major transition in life, birth, coming of age, marriage, and death, for example, is marked by a ceremony, these take place essentially in a family setting, and no centralized records are therefore kept. Even in the later period when records like birth certificates, high school graduation certificates, or passports exist, the birth date stated in them disagree with what is remembered by parents, celebrated as birthdays in the family (birthdays were often not celebrated at all), or written down in star charts etc. This probably resulted from parents' attempts to allow their children to get around retirement age rules or from a child being born just after the beginning of a school year so that they do not have to wait an extra year before joining school. However, such mismatch may sometimes indicate other problems in the records, or with people's memories.
Leaving aside the question of dates, most caste Hindu families, till recently, maintained a genealogical record of the names of the male ancestors, often with annotations when the joint families split and people moved out, but these carry no information about dates or events from when these people lived. On this page, I discuss a few topics related to discovering my genealogy in this setting:
Please follow the links to visit the genealogy on my father's and mother's side if you are not interested in discussions. You may also download it as a zipped GEDCOM file, or view the same using a java applet. The GEDCOM file codes the conflicting information about births, etc., (usually dealing with certificate versus remembered dates) using multiple events as recommended in the GEDCOM spec, but the Java applet does not understand this and displays only the last coded (i.e., most unreliable information), and it does not display all the fields as notes either. Currently, detailed events, causes of death, immigrations, etc., and source citations are coded only in the GEDCOM file and not on the web pages; conversely, the GEDCOM file does not contain pictures or other multimedia content, or hyperlinks, that are present in the web pages.
Indices of all names appearing in the genealogy on my father's and mother's side are available. These are, however, often out of date.
The primary source of these genealogies are lists maintaind by the individual families. For my father's side, I got a handwritten document which has obviously been copied through the generations. The document is in Sanskrit written in Bengali script, though sometimes the spellings and grammar are incorrect. For my mother's side, I got a chart but I have not been able to track down the original document on which it was based.
The first treatises on Brahmin genealogy in Bengal were written in about the 15th (dhruvAnanda's mahA-vaMshAvali) and 16th/17th (nulo pancAnana's goSThi-kathA, vAcaSpati mishra's kula-rAmA) centuries (incidentally, of the non-brahmin ones, the vaidya ones are 17th century, the rest 17th/18th century). But, the interest in genealogy is much older: sambdandha viveka by bhava-deva bhaTTa written during the sena period (11th–12th century) mentions the tradition of prescribed exogamy rules that required the recitation by the bride and groom of the names of their direct ancestors along the male line for seven generations from their fathers and five generations from their mothers. The early part of the genealogy on my father's side overlaps with the traditional stories, but disagrees with them. Such disagreement is common in this early part, see here for an example of comparison of a few different sources.
The last part of my genealogy (overlapping with the generations where the list ends) is from my own experience. Some of the branches distantly related to me are gathered from my relatives closer to them: I may have misunderstood or misremembered some of their statements.
My cousin Pritam also made a chart from roughly the same sources, but got slightly different names in a few places. I have mentioned the differences in the appropriate places to indicate uncertainty.
bhaTTAcAryya has been used as a family name only recently. Branches of my father's family have also used cakra-varttI, whereas my mother's family was caTTopAdhyAYa.
On my mother's side I can find the names of only the male ancestors for fifteen generations before my mother. At this time, a bhava-nAtha caTTopAdhyAYa of kAshyapa gotra lived in nala-ciD.A village in the nimana-dvipa region in bari-shAla. Two of his sons moved to brahmaNabAD.iYA and vaMshavATI, but my mother was descended from mAdhava who stayed in nala-ciD.A. My great grandfather, kAminikumAra, moved to West Bengal from barishAla.
On my father's side, family tradition has it that 30 generations before me, a brahmin by the name of veda-garbha came to Bengal from kAnya-kubja during the reign of AdishUra. (Such stories are actually quite common in different families. See the page describing one set of traditional stories about the origin of brahmins in Bengal.) He was of sAvarNa gotra and his five pravaras were bhRgu, cyAvaNa, ApluvAna, aurva, jAmadagni.
Eight generations after him, roSAkara brahmacArI started the kunda dynasty to which we belong. He was the teacher of the reigning king of Bengal, vallAla sena, who decided to separately recognize the high kulIna brahmins from the rest (See the page describing the traditional story of brahmin origin in bengal for more details). As it would be improper of the king to pass judgement on his own teacher, he decided to delegate the responsibility of drawing up this list to another brahmin in the court. By court intrigue, this resulted in our family not being classified as ‘kulina’. roSAkara was enraged and cursed the person responsible to be without descendants. The curse apparently worked.
Ten more generations later (i.e. 12 generations before me), of two brothers maGgalAcAryya and kRSNadAsa, the latter moved from shrImad vikrama-pura to the Doma-sAra village, whereas the sons of the former (raghu-nAtha, who might have been the first Bhattacharyya in the family, and gopI-nAtha, who might have been the first Chakravartti) moved with their deity to moSakAThI (or moD.AkAThI as it is later called), where they were brought by a king rAma-candra. If this person is the same as Raja Ramchandra of Bakla, famous for his association with the Baro Bhuiyans, this is in the early 1600's when Delhi was under the rule of Jehangir and just around when Khurram, later Shah Jahan, was amassing power as governor of Bengal. It is interesting to note that our family had land in bholA which adjoins Noakhali, and that entire region was called bhuluA before 1668 (the new canal was dug in 1660 AD to divert the dangerous waters of the Dakatia river), and the most famous stories of Ramchandra involve him defeating lakSmInAraYaNa of Bhulua.
Our family descended from this raghu-nAtha, though the genealogy mentions other branches of the family that dispersed at this time (i.e. 9 to 7 generations back from today): those settled in nau-dhulI (or dhUla), tAra-pAshA, shIkAra-pUra, bATA-jora, bAishI (or baishAD.i or rAishArI), harita-pura, ujira-pura, bhArtsAlA (or bharti-sAlA), caita-pura, and nabalA villages.
It is also around this time, some three to four hundred years back as we settled in these villages, that the genealogy starts using the titles Bhattacharyya and Chakravartti for the first time. In as few as a century and a half, most branches of the family regularly start using Bhattacharyya almost certainly as a last name and not merely as a title. This seems to be true even of most of those branches descended from people with a title of Chakravartti.
About one to three generations back from me, many of the branches in the family tree die out, and the rest migrate to different places. My grandfather yAminI and granduncle nalinI moved to Calcutta and we, their descendants, settled in various places.
The story of my father's family cannot be correct in the form stated. First, vallAla sena's guru was aniruddha of shANDilya gotra from campAhiTi. Second, the inscriptions of that period do not show any evidence that he started the kulina system. Third, he was a shaivaite, and our family, at least later, was shAkta, i.e., when we get dIkSA (initiation), it is a mantra (sacred words) belonging to kAli. (Our kuladevata is however nArAYaNa.)
However, vallAla sena's son lakSmaNa sena was a vaishnavite, and halAYudha of kAshyapa gotra was in his court and had a descendant shobhAkar who lived in AYdA (a few miles Southwest of Kalna) and was the guru of devivar who divided the kulinas into mels in 1482 AD. A story exactly similar to roSAkara is told about shobhAkara (ডাক দিয়ে কয় দেবীবর। নিষ্কুল শোভাকর॥ ডাক দিয়ে কয় শোভাকর। নির্বংশ দেবীবর॥), and shobhAkar's descendant rAma is known to have given the initiation to his own son viSNu siddhantavAgIsha, father of rAmadeva tarkavAgIsha and grandfather of vANeshvara vidyAlaGkAra who left the court of krISNachandra, ruler of krISNanagar, and wrote citrachampu in 1714 (or 1744) for chitrasena, king of varddhamAna, son of kIrtichandra, son of jagatrAYa, son of kriSNarAma who was contemporary of shobhAsiMha who in 1696 collaborated with the pAThAns from Orissa.
What is far more interesting is the relation of the sAvarNa gotra with the varmaNa dynasty. Not only did shyAmalavarmA's son give land grant to a brahmin of sAvarNa gotra who came from Uttar Pradesh, his own minister bhavadeva bhaTTa was from the same village. As shyAmalavarmA (East bengal) is associated with the origin of vaidika brahmins, just as vallAla sena (West bengal) is associated with the rADh.i and vArendrI brahmins; and given that the early part of our genealogy conflicts with the traditional stories; the most likely explanation is that the stories involved have gotten mixed up. In this context, it is also interesting that the Y DNA evidence points to a late arrival of our family in India, and the texts from the brahminical period refer to shAkadvIpI brahmins who may be related to the historical shaka migrations. Since these brahmins formed the numerous lower stratum of the brahmin hierarchy in daily contact with the common man, his needs and his rituals, a desire for upward mobility might have led to their incorporation into the higher strata.
Furthermore, 22 generations later, today, it is 1999. So, if the traditional association with vallAla sena is correct, as vallAla sena ruled in the third quarter of the 12th century AD this would say that there were about 2.6 generations per century, or about 37 years per generation on the average. This is actually quite unlikely: A number between 25 years to 30 years per generation is what is usually considered reasonable, and I would expect 17 and 35 to be outer limits for an average over this length of time. If veda-garbha instead was during Adishura (during whose time, according to one story, brahmins are supposed to have come to Bengal), we get 29-30 years if he was in 999 shAka year (see next paragraph). This is to be compared against a 1937 study showing that in the bengali kulina brAhmaNa and kAYastha families, the average male to first male child generation time was then about 27 years. In addition, one should note that if indeed the Ramachandra mentioned in our genealogy is the same as Raja Ramchandra of Bakla, then again we find a count of about 35 years per generation. This, of course, is not the time to the first child: in this period, it was, on average, the time to the second son, but, even then, it is longer than the expected 30–32 years. Given that we were not kulins, and possibly consequently, not too much polygamy or childhood marriages, may be the family is indeed atypical in its long generation time.
On the other hand, it is true that our (my fathers's side, that is) family still does not have a guru family (we take dikSA from other members of the family). Also, most brahmin traditional stories in bengal claim to originate during either vallAla sena (the brahmins in this story actually came during AdishUra's time; tradition attributes the year 999 to this event. Unfortunately, it is not clear whether that is meant to be the shaka or samvat era) or shyAmala-varmA (these brahmins claim they came during his reign). It is in this context that the 12th century reference to a person of our gotra having come from outside is particularly interesting.
Similarly, the generation number is also unlikely to be incorrect. Because of the marriage rules only people with the same generation number could marry each other, and it was very important t get the generation number right. In fact, a 1937 study showed that the generation numbers of bengalee kulina kAYastha between 20 to 30 years old clustered between 26 and 29, with some outliers as low as 23 and as high as 30.
Historically, the gotra to which my father's family belongs (sAvarNa) is mentioned in the 12th century: bhoja-varmA of varmana dynasty gave land in paunDra-bhukti to a brahmin rAma-deva of sAvarNa gotra with pra-varas bhRgu, cyAvaNa, ApluvAna, aurva, jAmadagni, who was of vAja-saneya caraNa of the yajurvedIYa kANvashAkha, who was a shantyAgArika, and whose ancestors had come from madhya-desha to siddhala village in northern rADh.a. siddhala village was known to have many sAvarNa brahmins also during varmana king hari-barmA. It is to be noted that almost the same pra-varas (jAma-dagnya instead of jAma-dagni) is also attested for a family (ratnAkara to rahaskara to bhAskara to udayakara) from madhya-desha of vatsa gotra of AshvalAyana shAkha of Rgveda during vijaya-sena's rule.
During hindu marriage, exogamy rules prescribe that the bride and the groom have to recite the names of their direct ancestors of their father and mother along the male line for seven generations and the female line for five generations. This tradition is mentioned in sambandha viveka composed by bhava-deva bhaTTa. So, at whatever point the genealogy was written down, seven generations up from that point are likely to be correct. From the first appearance of details about village etc., and assuming that a person is likely to remember details of his grandfather, and possibly great grandfather, it is reasonable to conclude that 21. rAma-jIvana was one of the people who wrote down the genealogy. This would imply that, barring deliberate falsification and copying errors, starting at 14. vatsa, one can start trusting the genealogy as historical fact.
I should also note that 1. veda-garbha through 9. rashmi-kara is attested by the traditional stories of origin of Brahmin in Bengal: and it would make sense for myths of origin from this family to occur; though our genealogy actually disagrees with the traditional one, probably by the usual confusion of cousins being counted as on the direct line. That 14. vatsa to 17. jana-mejaYa is missing from one of the lists needs further investigation.
On my mother's side, the Nalchira village appears in the beautiful compilation of stories of abandoned villages ‘ছেড়ে আসা গ্রাম’ (Chhere Asha Gram) compiled and edited by Dakshinaranjan Basu. It mentions that the Bhattacharya household in this village had 14 tols (schools) and a ‘world-conquering’ ‘Jagannath Tarkapanchanan’ lived there, because of whom the place was called nimna-nabadvip (lower nabadvip, nabadvip being the center of knowledge, probably the same as nimandvip in the genealogy). Whether this person was related in some way to the 5. Jagannath Panchanan that appears in our genealogy needs further investigation. The famous Jagannath Tarkapanchanan who wrote the hindu texts, was at the court of Krishnachandra Roy of Nadia/Krishnanagar, lived 1694–1807, and was a resident of Triveni, so he must be a different person.
As mentioned above, the spread in generation numbers currently is about 10%. Assuming this was the case in the past (The times are short enough that I am ignoring the averaging effect which makes the percentage spread fall off as the square root of the mean number of generations), and assuming the minimum and maximum average generation times are roughly 29 and 40 years respectively (see above), we get the following approximate table for my father's family (for the early parts, I have used the constraints that vallAla sena of the 12th century made some people of generations 8–11 kulinas). Note that the spread in the generation numbers in this family is somewhat smaller, and prefer the generation numbers near the middle of the indicated range.
| Approximate time of birth | Generation range | Approximate time of birth | Generation range | Approximate time of birth | Generation range |
|---|---|---|---|---|---|
| 21st century | 25–38 | 20th century | 23–35 | 19th century | 21–31 |
| 18th century | 18–28 | 17th century | 16–24 | 16th century | 13–21 |
| 15th century | 11–18 | 14th century | 8–14 | 13th century | 6–13 |
| 12th century | 4–12 | 11th century | 2–8 | 10th century | 1–4 |
A similar calculation for my mother's family gives the following table:
| Approximate time of birth | Generation range | Approximate time of birth | Generation range | Approximate time of birth | Generation range |
|---|---|---|---|---|---|
| 21st century | 17–20 | 20th century | 14–17 | 19th century | 11–14 |
| 18th century | 7–10 | 17th century | 4–7 | 16th century | 1–4 |
Me (Cross hair) on a plot of World populations and an enlarged view of the region around me..
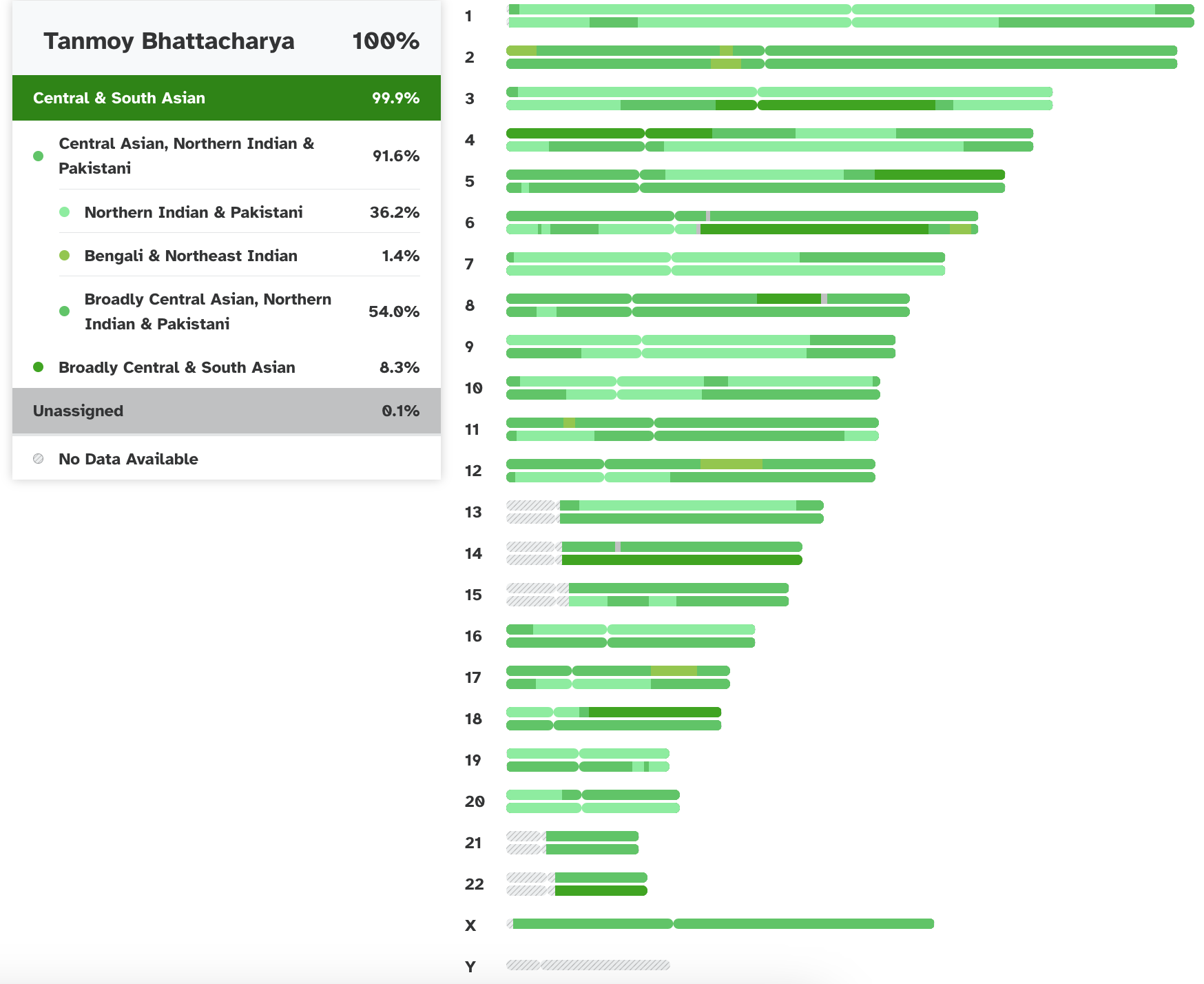
European (Blue), Asian (Red), and African (Green)
contribution to
the various autosomal chromosomes.
Grey indicates lack of information.
If we go back even a couple of thousand years, each of us had innumerable ancestors living around the world: two of these were however special in our ability to know about them. They are the unique male at that moment of time who is connected to us by an unbroken chain of male descendants (i.e. my father's father's .... a hundred times over ... father) and the unique female an unbroken chain of whose daughters bore me (i.e. my mother's mother's ... a hundred times over ... mother). It is reasonable to assume that these two did not know each other, or may even not have known about the existence of each other's clan, or, indeed, race. In my case, a matrilineal ancestor could have been one of the original modern human inhabitants of India, whereas a patrilineal ancestor may have belonged to the tribes who spread out from around the black sea, carrying with them the Indoeuropean language which ultimately gave rise to most of the European, Iranian, and North Indian languages. I describe this genetic story in the next sections.
Isofrequency map for the geospatial
distribution
of the light skin (European) allele of rs1426654(A). It
probably became the predominant European allele by 15±4 kya.
For the rest of the ancestors, we need to consider the autosomal DNA and the X chromosome: but this analysis is difficult. In fact, these results are, without sophisticated techniques, usefully analyzed only for placing one overall among the human populations and estimating the inbredness of the population. In this, I am as expected, placed squarely among the North Indians, in particular the UP-Bihar-Bengal brahmins, and am about 64% Ancestral North Indian, 32% Ancestral South Indians, with the rest showing affinities with the East Asians. My skin color gene SLC24A5 is homozygous at the locations rs16960620(A), rs2555364(G) and rs1426654(A), as in 99.4% of Europeans, but which is in only 8.7% of Asians and almost non-existent in Africans (See the paper for more details). The Brahmin populations in Bengal are fairly inbred, and this is also clearly visible in the autosomal results. The X and autosomal DNA can also be used to hunt for relatives, though the databases in the US have not helped much. Finally, traces of Neanderthal or other ancestry can sometimes be detected in this, though I have so far found only a bit (due to a bug in some browsers, the link does not go to the last section on premodern humans on that page: if so, please scroll down after following the link) in my DNA.
Our chromosomes come in pairs we inherit from our two parents. Similarly, each of our children obtains from us one chromosome corresponding to each pair. The chromosome we give to our child is, however, neither of the ones we got from our parents: Before we pass it to our child, we combine pieces from the chromosomes that we got from each parent in a process called recombination. Thus, some of the DNA in the chromosome that my child will get from me will have been my father's, and some other bits from my mother. After a few generations, each bit of my descendants' DNA will have had a different origin, making it difficult to trace the ancestry except in a statistical sense.
There are however two exceptions to this. The mitochondrial DNA that we inherit only from our mothers is passed on unchanged, except for small ‘errors’: there has been occasional claim of past recombination, but current evidence is strongly against it. The same happens to most of the DNA in the Y chromosome which is carried in one copy by the males, and except for tiny regions near the end, it can no longer recombine with the X chromosome. The genealogy of the mtDNA is, thus, the genealogy along the female ancestral line (i.e. mother, mother's mother, and so on), whereas the Y chromosome traces the male ancestral line. See here for a basic idea of how a Single Nucleotide Polymorphism test works.
Of course, one needs to be careful! The rate of error is such that every change in our chromosomes (including the sex chromosomes) can happen about 1–10 times in every billion births (YFull uses 0.8178 x 10-9 mutations per base-pair per year in a region consisting of 8,473,821 positions on the Y-chromosome that they think are useful–i.e., simple, not too many coincidences, and known well) and about 200 times more often for the mtDNA (and 10 times even faster in the hypervariable regions usually tested). In other words, since about 85 billion people have been born since the dawn of humanity, each marker could have arisen a few hundred times independently, and, with today's population, even in one generation there may be a few people who newly got that marker. A pair of markers, on the other hand, is very unlikely to have originated independently even once in the history of humanity, and when we see a shared pair, neither of which are in locations susceptible to unusually fast change, we can deduce that a genealogical connection was responsible for at least one of the markers. The slow mutation rate means that the common ancestor may have been a long time back; conversely, since the probability of a marker changing back is also negligible, very old ancestral relations are still visible in these studies.
The above mathematics applies to the base-substitution markers: there are also microsattelite (or minisattelite) studies, and the STR analysis described below (for Y-chromosomes) falls into this class. These change much faster (see here for example): about one to ten in a thousand births change the same marker by chance (See here for example; and here for a nice table and analysis of the common cases), but there are many more values each marker can take. As a result, one needs to be careful that back mutations become a significant possibility in 5000 to 10000 years in every lineage, and the same mutation happening in two lineages is already likely in half that time. At time depths of hundreds of thousands of years, i.e. in the entire history of humanity, the method needs care: differences smaller than some 5 mutation steps at any one position are almost completely uninformative; but because of the same fast mutations and multiple states, exact matches on many markers are rare by chance and imply shared ancestors much closer to us. As an example, assuming mutation probability of 2 in a thousand per generation per site, a very conservative estimate, the probability that at least one out of a random bunch of 12 of these markers changes within 14 generations is just under 30%, so there is just over 50% probability that two samples which match in these 12 markers exactly are from people more than 14 generations from a common ancestor. In a similar fashion, one can be 95% certain that there are no more than 62 generations to a common ancestor in this case. The mutation rates are probably considerably faster than this, so the expected number of generations are probably half of what I calculate in these pages.
Actually, what is an easier number to understand is the (95%) confidence interval: which is a range rather than a limit: for a twelve marker match, this is 1–77. Now, if we account for the fact that the markers might match because of similar or compensating changes, the quoted generation numbers become 15, 71, and 1–89 respectively. Since, as discussed before, a generation time is likely to be about 25 years, a twelve marker match means that there is about a 95% probability that the last common ancestor was around the beginning of the common era. But note that even then there were enough people so that the 5% probability event must have happened: i.e. occasionally one must find people whose common ancestor is much earlier or later than what this analysis suggests.
Some people would estimate using a much higher rate, and get half the number of generations as these, e.g., the 95% CI is quoted between 1–38 or 1–45 depending on the model used. The page dealing with DNA analysis at the Blair genealogy project gives an informative table of these numbers; and the site used by Family Tree DNA gives a detailed discussion and graphs.
All of the above assume that the markers have been chosen at random. This is obviously not true: the markers are chosen by researchers on the basis of the observed variation being useful in determining population structures. This could bias the calculations towards finding dates closer to the time that various previously defined populations separated, but the amount of bias cannot be judged. On a similar note, the effects of small populations, and, what turns out to be very similar, effects of extreme differences in the number of descendants various individuals have, is also ignored.
The National Geographic genographic project analyzed my Y chromosome. Augmented with further tests I paid for, the following copy numbers of Short Tandem Repeats at various positions were found:
| DYS | 393 | 390 | 19/394 | 391 | 385a* | 385b* |
|---|---|---|---|---|---|---|
| value | 13 | 25 | 16 | 11 | 11 | 14 |
| rate | 0.29–1.72 | 1.47–3.62 | 1.55–3.67 | 1.83–4.18 | 1.41–2.98 | F |
| DYS | 426 | 388 | 439* | 389-1 | 392 | 389-2 |
| value | 12 | 12 | 10 | 14 | 11 | 32 |
| rate | 4.19–9.22 | 1.41–3.74 | 0.12–1.17 | 2.24–5.02 | ||
| DYS | 458* | 459a | 459b | 455 | 454 | 447 |
| value | 17 | 10 | 10 | 11 | 11 | 24 |
| rate | F | F | F | |||
| DYS | 437 | 448 | 449* | 464a* | 464b* | 464c* |
| value | 14 | 20 | 32 | 15 | 15 | 16 |
| rate | F | F | F | F | ||
| DYS | 464d* | 460/GATA-A7.1 | GATAH4 | YCAIIa | YCAIIb | 456* |
| value | 16 | 12 | 12 | 19 | 23 | 15 |
| rate | F | F | ||||
| DYS | 607 | 576* | 570* | CDYa* | CDYb* | 442 |
| value | 16 | 19 | 18 | 36 | 42 | 14 |
| rate | F | F | F | F | ||
| DYS | 438 | |||||
| value | 11 | |||||
| rate | 0.06–1.69 |
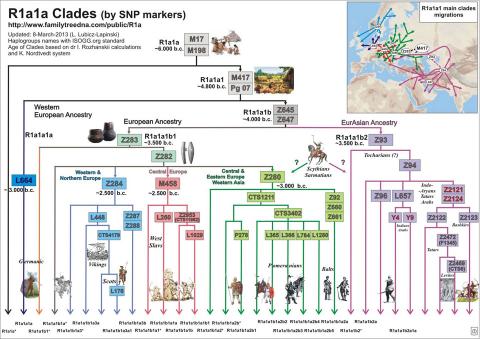
R1a1a Clades from Family Tree DNA: Updated 8 Mar 2013
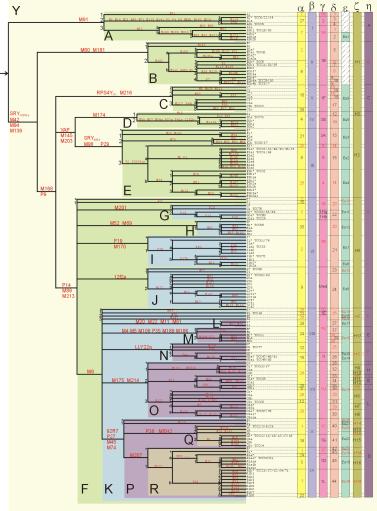
From the markers, I was classified as a R1a1a(M17)—new tests from 23andme (see here for the SNP results) and there are close STR12 matches for me belonging to R1a1a1b2a1a(L657.1/S347.1)—by SNP typing (M124- M157- M269- M343- M56- M64.2-? M87- P25- SRY10831.2- M17+ M173+ M198+ M207+; just like 72% of the West Bengal Brahmins). Later, I had my ‘full genome’ done from Dante Labs and had the Y chromosome analyzed by YFull. This led to many more STRs and SNPs. All this showed I am actually R1a1a1b2a1a2c (Y7) with additional Y30, Y29, Y944, Y2439 and Y2428, but not Y16494 (which is provisionally R1a1a1b2a1a2c2d5~xa, or R-Y2428). Looking at the pattern of my close STR matches, I suspect that 12 marker STR matches probably do not give a resolution better than pointing to R1a1a1b (R-Z645 in YFull notation) (PF6162/S224/V1754/Z645), which has a time since most recent ancestor of 5000 years before present (and a 95% confidence interval of 5400–4500 ybp), and which was former around 5400 years back (95% CI: 6000–4700 ybp) according to YFull. This is more than double the estimate one comes up with naïvely. So, some of the markers, at least, must have a slower rate of change, or are constrained so that they converge to the same state in multiple disjoint clades. Incidentally, all these subgroup names are in the 2020 (ISOGG v15.58) nomenclature, the haplogroup names keep changing over time, though this part has not changed in a couple of years: see here for a history of the Y tree. As shown in this diagram, before the cladistic nomenclature started, even the top branches have been variously named as belonging to haplogroup 3, IX, 1D, 45, Eu19, H16, or D, according to classification systems adopted by various authors.
The history of this haplotype is as here. In summary, the R1a1 (R-M459) group probably arose about 20 thousand years ago around the Hindukush mountains (or in Pakistan), and the depth of R1a1a is about 15–16 thousand years in the Pakistan-West India region (YFull estimates the origin to be 18.2Kabp with 95% confidence interval to be 16.4–20.1Kabp, and the depth to be 14.1, 95% CI 12.5–15.7, Kabp). From there it may have spread across Nepal and India and to the north-east, reaching the Caucasus about 12 thousand years ago. From there it seems to have spread to the Southwest through Turkey to Hungary and Greece, the Southeast to Iran, and northwards through Russia. Italy and Kyrgyzstan may have been the last major expansions into fresh territories probably 5.9 and 5.6 thousand years ago. (The eastern European expansion is of the R1a1a1b1 which may have arisen in Poland about 11 thousand years back, and started spreading by about 8500 years back; though YFull estimates it to be much younger—origin of 5 (4.5–5.6) Kabp and depth of a 100 years less than that.
There is some reason to believe that the R1a (R-M420) were the ancestors of the people who spread the Indoeuropean group of languages into Asia, and possibly the Steppes people that domesticated the horse. Of course, if, as seems likely, the R1a haplotype arose thousands of years (YFull estimates: depth 18.2 (16.4–20.1) Kabp, origin 22.8 (20.5–25.1) Kabp) before the origin of the Indoeuropean group of languages (probably 5–10 Kabp), it probably was present indigenously in various places including India before the advent of Indoeuropean speaking people. Conversely, this late in human history in such a populated region, the amount of linguistic conversion and cultural adoption is expected to be great enough that the people speaking predominantly Indoeuropean languages could often harbour a mixture of haplogroups, and ‘Indoeuropean migrations’ in various regions could even be predominantly represented by different haplotypes. In fact, though R1a1a (M17 and M198; origin 14.1 (15.7–12.1) Kabp; depth 8.5 (9.8–7.3) Kabp) is the most common haplogroup associated with the Indoeuropeans, R1b1a1 (P297; origin 15.6 (17.6–13.8) Kabp; depth 13.3 (14.9–11.8) Kabp) is also associated with some branches. See my pages on genetic composition of Bengal for more details.
In November 2007, a paper was published that reported sequencing results on DNA extracted from ancient Siberian mummies from the Krasnoyarsk region. Those from the Andronovo culture (2300–1000 BC), often associated with the Indo-Iranian innovations, had
DYS 19:16 385a:11 385b:14 389I:14 389II:32 390:25
391:11 392:11 393:13 437:14 438:11 439:10
448:20 456:16 458:15 635:23 YGATA:12
(Table 3 S10/S16) which is an exact match for me in the first 12 markers, and differs from me only at my 456:15 458:17, both of which are probably fast markers. Using the standard rates of change, in a single lineage (as opposed to two lineages we were calculating before), the chance of perfect preservation of 12 arbitrary markers in these intervening 3500 or so years, or 125 or so generations, is about 5%; though as pointed out before, it is likely that these calculations are too young in timing by a factor of about 2. From YFull calculations and observations, the common ancestor with me may have lived as far back as 1100–1800 years before the start of the Andronovo culture. Four samples from the Tagar culture were different at 1, 3, 4, and 5 positions, whereas the one sample from Tachtyk culture was different at four places. No data was available from the Afanassievo culture. Another study that looked at later Mongolian mummies from the Xiongnu period (3rd century BC–2nd century AD) found at least one (Egyin Gol #70) which had only 1/10 differences (in the fast moving 389) (19:16, 390:25, 391:11, 392:11, 393:13, YCAII:19/23, 385:11/14, 389II:31) from me.(#72 and #73 couldn't be determined and #65 might be distantly related.)
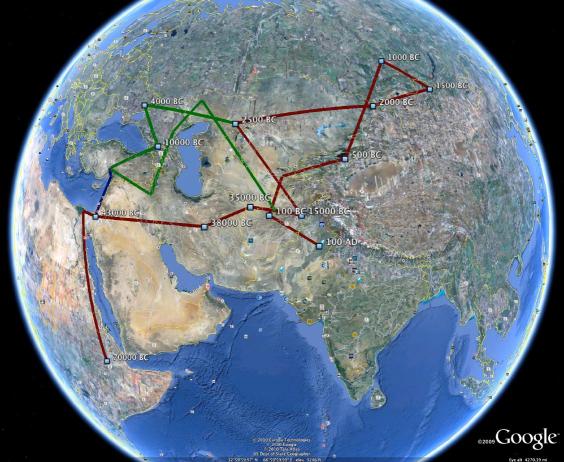
A possible route that brought
my paternal chromosome from Africa to India. The
period from 38000 BC to 10000 BC is probably one of
range expansion by diffusion, or splinter group movement,
of people with various haplotypes to the west, to the
north, and to the east into India; the R1b descendants (green)
of the R1 people went to Europe and influenced
the R1a1 people culturally and linguistically.
Here is the kmz file
that generated the picture.


More likely, we did not detour through Siberia, but
are closely related to people that actually went there.
Shown is, for example, the likely genetic makeup of some
prominent cultures and the spread of the Yamnaya people
according to the currently accepted dates. See the text
for details.

The topography of
the Krasnoyarsk-Almaty-Afganistan-Pakistan-India
region.
Link to Google
Maps.
Given this data alone, and close matches to my genotype around Central Asia, we cannot be certain which wave of people my ancestors came into India with, and the large number of 12 STR matches in the Kazakhstan-Siberian region do not seem very informative if they support a last common ancestor at a time depth of 5000 ybp. The analysis for the entire R1a1a1b2 (R-Z93) branch presented here, concluded this already on the basis of the STRs. In particular, this analysis reconstructs ancestral L657+ (R1a1a1b2a1) as 456:15 458:16 and so on the basis of my 456:15 458:17, and further on the basis of my 447:24, concluded I am Z93+ L657+ Y7+ [i.e., R1a1a1b2a1a (which I now know to be correct)]; as opposed to Siberian expected Z93+ L657- (i.e., R1a1a1b2xa1), and explains the Babasan Kazakh L657+ Y7+ as due to late (during Kuchum Khan, c. 1556AD) Arab missionary activity carrying this haplotype (it having reached into the Arabs long back) to there. The L657 split probably has a TMRCA of 4100 ybp, with a 95% CI of 4600–3700 ybp according to YFull analysis. In this respect, it is interesting that Genetic Homeland finds three Y2428 terminal samples: one each in Barisal in Bangladesh, Punjab in Pakistan, and Aqmola in Kazakstan. So, the Kazakh group could indeed be a recent descendent of Y2428 whose most recent common ancestor is 3600 (95% confidence interval 4400–2800) years back, and not merely Y7 from 3900 (4500–3300) years back. This is further supported by Family TreeDNA, which shows that though of the Y2428 among their testers, 7 trace their ancestry to Kazakhstan, 3 to India, the rest 4 to other countries such as Iraq, and they date the branching off of this lineage to 2700±650 years back, the Kazakh samples are all (2 R-B132→R-25015→R-24681, 2 R-B132→R-25015*, 2 R-B132→R-FTC38562, and 1 R-B132*) descendend from the recent R-B132 where the 95% confidence intervals for the date of R-25015 is 1793–1956 AD, of R-FTC38562 is 1783–1968 AD, and of R-B132 is 1326–1691, fitting in nicely with the Arab missionary activity scenario. These are all descendants of R-Y2428→R-16494, which has a 95% confindence interval on its date as 1195 BC–90 AD and its other branches are represented in India, Pakistan and the Arab countries.
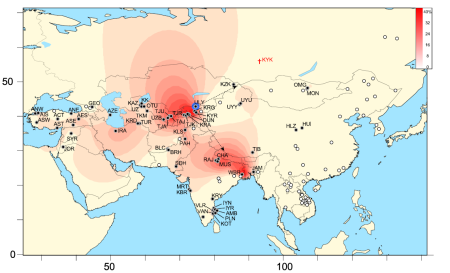
Distribution of the second largest (estimated 95%
confidence interval [0.6,1.2]% of all men) descent
cluster among Asian men that probably dispersed from
Central Asia (or N. India or Tibet) around 1000BC (n=271,
radius:6, mean 1270BC, median 175BC, 95% CI: 20908BC–
1792AD),
assuming a mutation rate of 9.33 x 10-5 per locus
per
year (0.0028/gen, 30yrs/gen) and exponential growth
(estimated
rate 3087). Maximum diversity among the Uyghurs.
(Figure from
supplemental information of Balaresque
et al.)
Despite all this, if the Andronovo match not be coincidental after all and the many other Siberian 12 marker matches not be late in origin, we may not have been part of the original migration of Indoeuropean peoples into India 4000–3500 ybp. In this scenario, we can hypothesize our ancestors reached the Krasnoyarsk region-Egiin Gol valley about three and a half thousand years back (though the fact that the 4Ka BP samples from the Xiaohe cemetery in the Tarim basin had R1a1a haplotype and Siberian/Central Asian mitochondrial DNA might argue for an older date), then moved to the Amaty-Ili valley region at some point, and a branch moved out of there around the time of Christ and came to India. A recent paper points out that our STR signature (19:16 389I:13/14 389b:18 390:25 391:11 392:11 393:13 439:10) probably belongs to the second largest descent cluster among Asian men, and started expanding from Central Asia around 1000BC (see caption at right for details). In fact, at least two historical migrations from that region, all the way to Transoxiana and Bactria and into India right around 2000 years back is known: the Shakas and the Kushanas, as they are known in Indian history. The story of these groups is briefly as follows: The Yuezhi (月支) (possibly the same as the Tocharians) who were thrown out northwestward out of their homeland, possibly near the Tarim basin-Gansu region, in northwestern China by the Xiongnu around 177 BC, after settling in the Ili valley and forcing the Sakas settled around Issyk-Kul to move southwards to Bactria and India (where they are called Shakas, and are possibly related to the horse people, Kambojas), were themselves forced to move south by the Uysyns/Wusuns by about 155BC. They finally reached India through Transoxiana and Bactria by the first century AD, posibly earlier, at a time when the Guishuang (貴霜) tribe amongst them was in control, and were called Kushanas (possibly related to Rishikas) in later history here. The traditional stories of shAkadvIpI brahmins in Bihar and Bengal with a homeland in central asia is particularly interesting in this regard.
Little is known about the STR distribution among Bengali brahmins today: more than 80% of them, however, belong to the R1a1. From anecdotal information, I know that people with Bandyopadhyaya and Chattopadhyaya last names (and other brahmins of the same gotra) are often this haplogroup (the rest are usually R2); and they are typically 8–10/29 steps away in STRs. This would correspong to a modal value of about 40–50 generations, or about 1000–1250 years, to the last common ancestor. The only Gangopadhyaya whose genotype I know, who, being the same gotra as me, is supposed to be closer, is actually of O2 haplogroup; though an Arghya Bhattacharya belonging to the same gotra as me is indeed R1a1 and only 2/16 steps away, coresponding to a modal 30 generations, or 750 years, to the last common ancestor. His earliest known ancestor along the male line, Umanath Bhattacharyya, lived in Calcutta c.1810–c.1900, and does not appear in my genealogy.
The hypervariable region 1 of my mtDNA was sequenced and found to differ from the cambridge reference sequence
16001 ATTCTAATTTAAACTATTCTCTGTTCTTTCATGGGGAAGCAGATTTGGGTACCACCCAAGTATTGACTCA
CCCATCAACAACCGCTATGTATTTCGTACATTACTGCCAGCCACCATGAATATTGTACGGTACCATAAAT
ACTTGACCACCTGTAGTACATAAAAACCCAATCCACATCAAAACCCCCTCCCCATGCTTACAAGCAAGTA
CAGCAATCAACCCTCAACTATCACACATCAACTGCAACTCCAAAGCCACCCCTCACCCACTAGGATACCA
ACAAACCTACCCACCCTTAACAGTACATAGTACATAAAGCCATTTACCGTACATAGCACATTACAGTCAA
ATCCCTTCTCGTCCCCATGGATGACCCCCCTCAGATAGGGGTCCCTTGACCACCATCCTCCGTGAAATCA
ATATCCCGCACAAGAGTGCTACTCTCCTCGCTCCGGGCCCATAACACTTGGGGGTAGCTAAAGTGAACTG
TATCCGACATCTGGTTCCTACTTCAGGGTCATAAAGCCTAAATAGCCCACACGTTCCCCTTAAATAAGAC
ATCACGATG 16569
by transitions at the five marked positions: T16093C (i.e. I have C instead of T), G16129A, C16223T, T16519C, and C16527T. An exact match to this entire region would mean, with 95% certainty, that the last common ancestor along the female line lived after the beginning of the Indus valley (or Saraswati-Sindhu) civilization. No such match is there in the database, but the positions 16401 to 16568 are not tested as often. There are three matches found in the first 400 positions alone (1/2342 from Ireland and 2/1792 from United Kingdom ), but they may be from the I haplotype, a N* descendant, instead of being closely related. 1/143 match from India is indeed M*. A Radhabai Subramanian born around 1920 and a Padma Ramaswamy born in 1931 in India (the latter in Courtallam, Tamil Nadu) differ only by not having the 093C mutation, and are the closest people whose details were available, I have not been able/tried to contact tnem.
A similar test of the second hypervariable region showed differences, at the marked positions, from the CRS:
1 GATCACAGGTCTATCACCCTATTAACCACTCACGGGAGCTCTCCATGCATTTGGTATTTTCGTCTGGGGG GTATGCACGCGATAGCATTGCGAGACGCTGGAGCCGGAGCACCCTATGTCGCAGTATCTGTCTTTGATTC CTGCCTCATCCTATTATTTATCGCACCTACGTTCAATATTACAGGCGAACATACTTACTAAAGTGTGTTA ATTAATTAATGCTTGTAGGACATAATAATAACAATTGAATGTCTGCACAGCCACTTTCCACACAGACATC ATAACAAAAAATTTCCACCAAACCCCCCCTCCCC—CGCTTCTGGCCACAGCACTTAAACACATCTCTGCCA AACCCCAAAAACAAAGAACCCTAACACCAGCCTAACCAGATTTCAAATTTTATCTTTTGGCGGTATGCAC TTTTAACAGTCACCCCCCAACTAACACATTATTTTCCCCTCCCACTCCCATACTACTAATCTCATCAATA CAACCCCCGCCCATCCTACCCAGCACACACACACCGCTGCTAACCCCATACCCCGAACCAACCAAACCCC AAAGACACCCCCCA 574
by transitions A73G, A93G, A263G, and T489C and by an insertion —315.1C. The genetic markers classify me as coming from the M* stock. The 23andme results show the following differences from rCRS (according to mthap analysis):
73G, 263G, 489C in HVR2 709A, 750G, 1438G, 1719A, 1888A, 2706G, 3921T, 4454C, 4769G, 7028T, 8701G, 8860G, 9449T, 9540C, 10398G, 10400T, 10873C, 11719A, 12372A, 12477C, 12705T, 14323A, 14766T, 14783C, 15043A, 15262C, 15301A, and 15326G in CR, 16223T, (16519C), and 16527T in HVR1.
With the 16129A that I know this is 1719A, 9449T, 12372A, 16519C, and 16527T over M5a2ax1,2,3. My full dna sequence from Dante Labs analyzed by YFull gave a more complete list of differences from rCRS and from RSRS, and shows my haplotype as M5a2a6b.
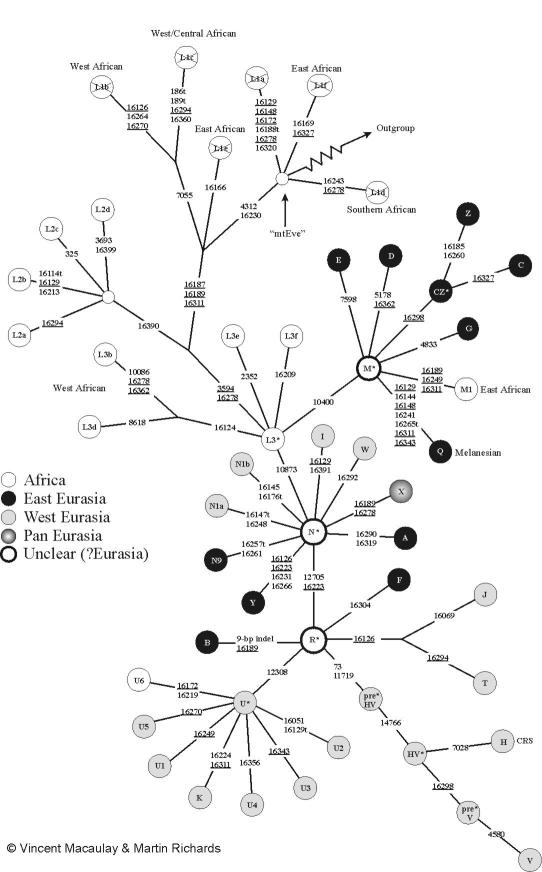
The story of this group (see here for the groups) is as follows: Starting about 190 (233.6–151.6) KYa, a series of mutations at rCRS 146, T182C, T4312C, T10664C, C10915T, A11914G, G13276A and G16230A (These do not show up as differences from CRS in my genome, because the CRS itself is a H2a2a1 sequence, which shares this history) separated L1–6 from L0 (mainly in Khoisans and the Sandawe) around 150 Kya. Following this, L1 (West and Central Subsaharan regions) separated and the mutations at 152, A2758G, C2885T, G7146A, and T8468C accumulated in L2–6. After the subsequent separation of L5, L2'3'4'6 accumulated 195, A247G, 825, T8655C, A10688G, C10810T, G13105A, T13506C, G15301A, 16129, T16187C, and 16189. After this L2 separated, and L3'4'6 got G4104A and A7521G. After L6 went their way, L3'4 got T182C, T3594C, 7256, T13650C and T16278C. Finally, about 80000 years ago, the African haplogroup L3 arose somewhere in Northern Africa with the mutations A769G and A1018G. Its daughters, M* (defined by T489C, C10400T, T14783C, and G15043A) and N*, both of which arose around 71–60 KYa, were the first to leave Africa. M* gave rise to M1 in Northern Africa or Arabia, my be as late as 45 KYa, and C, D, and Z around 60000 years back, somewhere possibly around Persia. The daughters of these populated large parts of east Asia and the Americas, but M* itself spread out to the Indian subcontinent, possible along the coastal Persia and Afganisthan; and then went on to Southern and Southeast Asia. M5 itself is defined by G1888A and 16129 and is found in S Asia. A subgroup of this M5a'd has G709A, C3921T, and G14323A. M5a itself is defined by T12477C and is found in East India, around Orissa. M5a2 is defined by T4454C; and M5a2a by T15262C. The C16527T them makes me M5a2a6, and the C9449T makes me M5a2a6b.
The CRS sequence which forms the basis of comparison arose from N*, defined by G8701A, C9540T, G10398A, C10873T, A15301G. R defined by T12705C and T16223C arose around 66 Kya somewhere in S. Asia from this, and R0 defined by A11719G arose from that sometime between 54.9 and 23.6 Kya in Asia. This lead to HV defined by T14766C around 25–30 Kya around the near East or the Caucasus, and H defined by G2706A and T7026C from that around 25–30 KYa somewhere near the middle east, probably arriving in Europe around the Gravettian culture. The mainly Eastern European, Caucasian and Central Asian subgroup, H2, contains a further G1438A, and H2a G4769A. Finally H2a2 is defined by G750A, H2a2a by G8860A, and G15326A and H2a2a1 by G263A. These will therefore appear as differences from CRS in my genome.
The 16093C mutation is very labile and is present in more than 7% of those belonging to M in India (in multiple subgroups: M7a2a, M9d, M10a1, M21a'b, and M22). In general, the haplogroup M is common among the ancient tribal populations of India, and rarer among the higher castes. Look here for a history of the various haplogroups of mtDNA and for distribution of these groups in the Indian population.
If browser supports, Yfull mtTree data reformatted to highlight relevant SNPs. The data is copylefted, scroll the window to top to see copyleft notice. Tooltips provide age information when available. The tree can be reformatted to display other sets of SNPs: instructions at top of the window. |
If browser supports, Phylotree data reformatted to highlight relevant SNPs. Note that the same SNPs appear in many branches, so one needs to look at multiple SNPs to find position in the tree. The data is copyrighted, scroll the window to top to see copyright notice. Tooltips provide information when available. The tree can be reformatted to display other sets of SNPs: instructions at top of the window. |
![]()
![]()
{kind=link}
{kind=link}